Hybrid Tables
A hybrid table is a Snowflake table type that is optimized for hybrid transactional and operational workloads that require low latency and high throughput on small random point reads and writes. A hybrid table supports unique and referential integrity constraint enforcement that is critical for transactional workloads. You can use a hybrid table along with other Snowflake tables and features to power Unistore workloads that bring transactional and analytical data together in a single platform.
Use cases that may benefit from hybrid tables include:
- Build a cohort for a targeted marketing campaign through an interactive user interface.
- Maintain a central workflow state to coordinate large parallel data transformation pipelines.
- Serve a precomputed promotion treatment for users who are visiting your website or mobile app.
Architecture
Hybrid tables are integrated seamlessly into the existing Snowflake architecture. Customers connect to the same Snowflake database service. Queries are compiled and optimized in the cloud services layer and executed in the same query engine in virtual warehouses. This provides several key benefits:
- Snowflake platform features, such as data governance, work with hybrid tables out of the box.
- You can run hybrid workloads mixing operational and analytical queries.
- You can join hybrid tables with other Snowflake tables and the query executes natively and efficiently in the same query engine. No federation is required.
- You can execute an atomic transaction across hybrid tables and other Snowflake tables. There is no need to orchestrate your own two-phase commit.
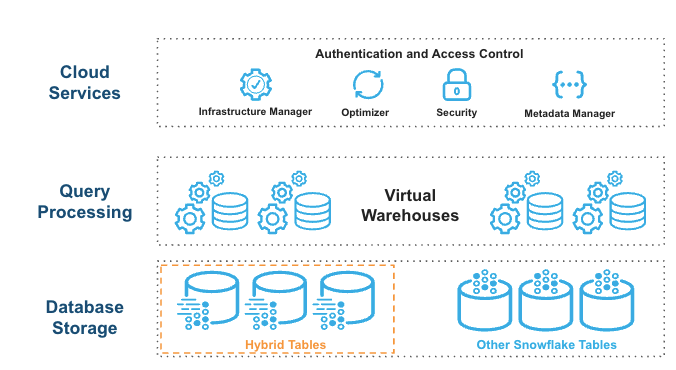
Hybrid tables leverage a row store as the primary data store to provide excellent operational query performance. When you write to a hybrid table, the data is written directly into the rowstore. Data is asynchronously copied into object storage in order to provide better performance and workload isolation for large scans without impacting your ongoing operational workloads. Some data may also be cached in columnar format on your warehouse in order to provide better performance on analytical queries. You simply execute SQL statements against the logical hybrid table and Snowflake's query optimizer decides where to read data from in order to provide the best performance. You get one consistent view of your data without needing to worry about the underlying infrastructure.
What You Will Learn
- The basics of hybrid tables
- How to create and use hybrid tables
- The advantages of hybrid tables over standard tables
- Hybrid table unique characteristics like Indexes, primary keys, unique and foreign keys
Prerequisites
- Familiarity with the Snowflake Snowsight interface
- Familiarity with SQL
- Snowflake non-trial account with Hybrid Tables enabled
- Account admin credentials which you should use to execute the quickstart
In this part of the step, we will setup our Snowflake account, create new worksheets, role, database structures, create a Virtual Warehouse and create two hybrid tables and one standard table that we will use in this step.
Step 2.1 Creating a Worksheet
Within Worksheets, click the "+" button in the top-right corner of Snowsight and choose "SQL Worksheet"
Rename the Worksheet by clicking on the auto-generated Timestamp name and inputting "Hybrid Table - QuickStart"
Step 2.2 Setup
Create Objects
Next we will create HYBRID_QUICKSTART_ROLE role, HYBRID_QUICKSTART_WH warehouse and HYBRID_QUICKSTART_DB database.
USE ROLE ACCOUNTADMIN;
-- Create role HYBRID_QUICKSTART_ROLE
CREATE OR REPLACE ROLE HYBRID_QUICKSTART_ROLE;
GRANT ROLE HYBRID_QUICKSTART_ROLE TO ROLE ACCOUNTADMIN ;
-- Create HYBRID_QUICKSTART_WH warehouse
CREATE OR REPLACE WAREHOUSE HYBRID_QUICKSTART_WH WAREHOUSE_SIZE = XSMALL, AUTO_SUSPEND = 300, AUTO_RESUME= TRUE;
GRANT OWNERSHIP ON WAREHOUSE HYBRID_QUICKSTART_WH TO ROLE HYBRID_QUICKSTART_ROLE;
GRANT CREATE DATABASE ON ACCOUNT TO ROLE HYBRID_QUICKSTART_ROLE;
-- Use role and create HYBRID_QUICKSTART_DB database and schema.
CREATE OR REPLACE DATABASE HYBRID_QUICKSTART_DB;
GRANT OWNERSHIP ON DATABASE HYBRID_QUICKSTART_DB TO ROLE HYBRID_QUICKSTART_ROLE;
CREATE OR REPLACE SCHEMA DATA;
GRANT OWNERSHIP ON SCHEMA HYBRID_QUICKSTART_DB.DATA TO ROLE HYBRID_QUICKSTART_ROLE;
-- Use role
USE ROLE HYBRID_QUICKSTART_ROLE;
-- Set step context use HYBRID_DB_USER_(USER_NUMBER) database and DATA schema
USE DATABASE HYBRID_QUICKSTART_DB;
USE SCHEMA DATA;
Create Tables and Bulk Load Data
In this quickstart, we will use Tasty Bytes Snowflake fictional food truck business data to simulate a data serving use case where we would like to serve data to our applications.
We will create three tables:
- ORDER_HEADER Hybrid table - This table stores order metadata such as TRUCK_ID, CUSTOMER_ID, ORDER_AMOUNT, etc.
- TRUCK Hybrid table - This table stores truck metadata such as TRUCK_ID,FRANCHISE_ID,MENU_TYPE_ID, etc.
- TRUCK_HISTORY standard table - This table will store historical TRUCK information, enabling you to track changes over time.
You may bulk load data into hybrid tables by copying from a data stage or other tables (that is, using CTAS, COPY, or INSERT INTO ... SELECT). It is strongly recommended to bulk load data into a hybrid table using a CREATE TABLE ... AS SELECT statement, as there are several optimizations which can only be applied to a data load as part of table creation. Bulk loading via INSERT or COPY is supported, but data loading is slower compared to CTAS, which could be 10 times faster, for large amounts of data and queries against freshly loaded data will be slower as well. You need to define all keys, indexes, and constraints at the creation of a hybrid table.
First we have to create a FILE FORMAT that describes a set of staged data to access or load into Snowflake tables and a STAGE which is a Snowflake object that points to a cloud storage location Snowflake can access to both ingest and query data. In this step the data is stored in a publicly accessible AWS S3 bucket which we are referencing when creating the Stage object.
-- Create a CSV file format named CSV_FORMAT
CREATE OR REPLACE FILE FORMAT CSV_FORMAT TYPE = csv field_delimiter = ',' skip_header = 1 null_if = ('NULL', 'null') empty_field_as_null = true;
-- Create stage for loading orders data
CREATE OR REPLACE STAGE FROSTBYTE_TASTY_BYTES_STAGE URL = 's3://sfquickstarts/hybrid_table_guide' FILE_FORMAT = CSV_FORMAT;
Once we've created the stage lets view using LIST statement all the files in FROSTBYTE_TASTY_BYTES_STAGE named stage:
-- List all the files in FROSTBYTE_TASTY_BYTES_STAGE named stage:
list @FROSTBYTE_TASTY_BYTES_STAGE;
The statement should return two records: one for the ‘TRUCK.csv' file and the second for the ‘ORDER_HEADER.csv' file.
Once we've created the Stage which points to where the data resides in cloud storage we can simply load the data using CTAS statement into our TRUCK table. The first DDL will create a hybrid table TRUCK using CREATE TABLE ... AS SELECT statement. Note the primary key constraint on the TRUCK_ID column. The second DDL will create a standard table TRUCK_HISTORY using CREATE TABLE ... AS SELECT statement.
-- current time step
SET CURRENT_TIMESTAMP = CURRENT_TIMESTAMP();
-- The first DDL will create TRUCK hybrid table using CREATE TABLE ... AS SELECT statement.
CREATE OR REPLACE HYBRID TABLE TRUCK (
TRUCK_ID NUMBER(38,0) NOT NULL,
MENU_TYPE_ID NUMBER(38,0),
PRIMARY_CITY VARCHAR(16777216),
REGION VARCHAR(16777216),
ISO_REGION VARCHAR(16777216),
COUNTRY VARCHAR(16777216),
ISO_COUNTRY_CODE VARCHAR(16777216),
FRANCHISE_FLAG NUMBER(38,0),
YEAR NUMBER(38,0),
MAKE VARCHAR(16777216),
MODEL VARCHAR(16777216),
EV_FLAG NUMBER(38,0),
FRANCHISE_ID NUMBER(38,0),
TRUCK_OPENING_DATE DATE,
TRUCK_EMAIL VARCHAR NOT NULL UNIQUE,
RECORD_START_TIME TIMESTAMP,
primary key (TRUCK_ID)
)
AS
SELECT
t.$1 AS TRUCK_ID,
t.$2 AS MENU_TYPE_ID,
t.$3 AS PRIMARY_CITY,
t.$4 AS REGION,
t.$5 AS ISO_REGION,
t.$6 AS COUNTRY,
t.$7 AS ISO_COUNTRY_CODE,
t.$8 AS FRANCHISE_FLAG,
t.$9 AS YEAR,
t.$10 AS MAKE,
t.$11 AS MODEL,
t.$12 AS EV_FLAG,
t.$13 AS FRANCHISE_ID,
t.$14 AS TRUCK_OPENING_DATE,
CONCAT(TRUCK_ID, '_truck@email.com') TRUCK_EMAIL,
$CURRENT_TIMESTAMP AS RECORD_START_TIME
FROM @FROSTBYTE_TASTY_BYTES_STAGE (pattern=>'.*TRUCK.csv') t;
-- The second DDL will create TRUCK_HISTORY standard table using CREATE TABLE ... AS SELECT statement.
CREATE OR REPLACE TABLE TRUCK_HISTORY (
TRUCK_ID NUMBER(38,0) NOT NULL,
MENU_TYPE_ID NUMBER(38,0),
PRIMARY_CITY VARCHAR(16777216),
REGION VARCHAR(16777216),
ISO_REGION VARCHAR(16777216),
COUNTRY VARCHAR(16777216),
ISO_COUNTRY_CODE VARCHAR(16777216),
FRANCHISE_FLAG NUMBER(38,0),
YEAR NUMBER(38,0),
MAKE VARCHAR(16777216),
MODEL VARCHAR(16777216),
EV_FLAG NUMBER(38,0),
FRANCHISE_ID NUMBER(38,0),
TRUCK_OPENING_DATE DATE,
TRUCK_EMAIL VARCHAR NOT NULL UNIQUE,
RECORD_START_TIME TIMESTAMP,
RECORD_END_TIME TIMESTAMP,
primary key (TRUCK_ID)
)
AS
SELECT
t.$1 AS TRUCK_ID,
t.$2 AS MENU_TYPE_ID,
t.$3 AS PRIMARY_CITY,
t.$4 AS REGION,
t.$5 AS ISO_REGION,
t.$6 AS COUNTRY,
t.$7 AS ISO_COUNTRY_CODE,
t.$8 AS FRANCHISE_FLAG,
t.$9 AS YEAR,
t.$10 AS MAKE,
t.$11 AS MODEL,
t.$12 AS EV_FLAG,
t.$13 AS FRANCHISE_ID,
t.$14 AS TRUCK_OPENING_DATE,
CONCAT(TRUCK_ID, '_truck@email.com') TRUCK_EMAIL,
$CURRENT_TIMESTAMP AS RECORD_START_TIME,
NULL AS RECORD_END_TIME
FROM @FROSTBYTE_TASTY_BYTES_STAGE (pattern=>'.*TRUCK.csv') t;
This DDL will create the structure for the ORDER_HEADER hybrid table. Note the following:
- Primary key constraint on ORDER_ID column
- Foreign key references constraints on column TRUCK_ID from table TRUCK
- secondary indexes on column ORDER_TS
-- Creates or replace ORDER_HEADER table
CREATE OR REPLACE HYBRID TABLE ORDER_HEADER (
ORDER_ID NUMBER(38,0) NOT NULL,
TRUCK_ID NUMBER(38,0),
LOCATION_ID NUMBER(19,0),
CUSTOMER_ID NUMBER(38,0),
DISCOUNT_ID FLOAT,
SHIFT_ID NUMBER(38,0),
SHIFT_START_TIME TIME(9),
SHIFT_END_TIME TIME(9),
ORDER_CHANNEL VARCHAR(16777216),
ORDER_TS TIMESTAMP_NTZ(9),
SERVED_TS VARCHAR(16777216),
ORDER_CURRENCY VARCHAR(3),
ORDER_AMOUNT NUMBER(38,4),
ORDER_TAX_AMOUNT VARCHAR(16777216),
ORDER_DISCOUNT_AMOUNT VARCHAR(16777216),
ORDER_TOTAL NUMBER(38,4),
ORDER_STATUS VARCHAR(16777216) DEFAULT 'INQUEUE',
primary key (ORDER_ID),
foreign key (TRUCK_ID) references TRUCK(TRUCK_ID) ,
index IDX01_ORDER_TS(ORDER_TS)
);
This DML will insert data into table ORDER_HEADER using INSERT INTO ... SELECT statement
-- This DML will insert data into table ORDER_HEADER using INSERT INTO ... SELECT statement
insert into ORDER_HEADER (
ORDER_ID,
TRUCK_ID,
LOCATION_ID,
CUSTOMER_ID,
DISCOUNT_ID,
SHIFT_ID,
SHIFT_START_TIME,
SHIFT_END_TIME,
ORDER_CHANNEL,
ORDER_TS,
SERVED_TS,
ORDER_CURRENCY,
ORDER_AMOUNT,
ORDER_TAX_AMOUNT,
ORDER_DISCOUNT_AMOUNT,
ORDER_TOTAL,
ORDER_STATUS)
SELECT
t.$1 AS ORDER_ID,
t.$2 AS TRUCK_ID,
t.$3 AS LOCATION_ID,
t.$4 AS CUSTOMER_ID,
t.$5 AS DISCOUNT_ID,
t.$6 AS SHIFT_ID,
t.$7 AS SHIFT_START_TIME,
t.$8 AS SHIFT_END_TIME,
t.$9 AS ORDER_CHANNEL,
t.$10 AS ORDER_TS,
t.$11 AS SERVED_TS,
t.$12 AS ORDER_CURRENCY,
t.$13 AS ORDER_AMOUNT,
t.$14 AS ORDER_TAX_AMOUNT,
t.$15 AS ORDER_DISCOUNT_AMOUNT,
t.$16 AS ORDER_TOTAL,
'' as ORDER_STATUS
FROM @FROSTBYTE_TASTY_BYTES_STAGE (pattern=>'.*ORDER_HEADER.csv') t;
In the previous Setup step we created HYBRID_QUICKSTART_ROLE role, HYBRID_QUICKSTART_WH warehouse, HYBRID_QUICKSTART_DB database and DATA schema. Let's use them.
-- Step 3
-- Set step context
USE ROLE HYBRID_QUICKSTART_ROLE;
USE WAREHOUSE HYBRID_QUICKSTART_WH;
USE DATABASE HYBRID_QUICKSTART_DB;
USE SCHEMA DATA;
We also created and loaded data into the TRUCK and ORDER_HEADER hybrid tables. Now we can run a few queries and review some information to get familiar with it.
View tables properties and metadata.
SHOW TABLES LIKE '%TRUCK%';
SHOW TABLES LIKE '%ORDER_HEADER%';
Display information about the columns in the table. Note the primary key and unique key columns.
--Describe the columns in the table TRUCK
DESC TABLE TRUCK;
--Describe the columns in the table ORDER_HEADER
DESC TABLE ORDER_HEADER;
Lists the hybird tables for which you have access privileges.
--Show all HYBRID tables
SHOW HYBRID TABLES;
List all the indexes in your account for which you have access privileges. Note the value of the is_unique column: for the PRIMARY KEY the value is Y and for the index the value is N.
--Show all HYBRID tables indexes
SHOW INDEXES;
Look at a sample of the tables.
-- Simple query to look at 10 rows of data from table TRUCK
select * from TRUCK limit 10;
-- Simple query to look at 10 rows of data from table TRUCK_HISTORY
select * from TRUCK_HISTORY limit 10;
-- Simple query to look at 10 rows of data from table ORDER_HEADER
select * from ORDER_HEADER limit 10;
In this part of the step, we will test Unique and Foreign Keys Constraints.
Step 4.1 Unique Constraints
In this step, we will test Unique Constraint which ensures that all values in a column are different. In table TRUCK that we created in the Setup step we defined column TRUCK_EMAIL as NOT NULL and UNIQUE.
Display information about the columns in the table.
-- Step 4
-- Set step context
USE ROLE HYBRID_QUICKSTART_ROLE;
USE WAREHOUSE HYBRID_QUICKSTART_WH;
USE DATABASE HYBRID_QUICKSTART_DB;
USE SCHEMA DATA;
-- Describe the columns in the table TRUCK
-- Note the unique key value for the TRUCK_EMAIL column
DESC TABLE TRUCK;
Note the unique key value for the TRUCK_EMAIL column.
Due to the unique constraint, if we attempt to insert two records with the same email address, the statement will fail. To test it run the following statement:
-- select one of the existing email addresses
SET TRUCK_EMAIL = (SELECT TRUCK_EMAIL FROM TRUCK LIMIT 1);
-- Since TRUCK_ID is a primary key we need to calculate a new primary key value in order not to fail on the "Primary key already exists" error.
SET MAX_TRUCK_ID = (SELECT MAX(TRUCK_ID) FROM TRUCK);
--Increment max truck_id by one
SET NEW_TRUCK_ID = $MAX_TRUCK_ID+1;
insert into TRUCK values ($NEW_TRUCK_ID,2,'Stockholm','Stockholm län','Stockholm','Sweden','SE',1,2001,'Freightliner','MT45 Utilimaster',0,276,'2020-10-01',$TRUCK_EMAIL,CURRENT_TIMESTAMP());
Since we configured the column TRUCK_EMAIL in table TRUCK as UNIQUE the statement failed and we should receive the following error message: "Duplicate key value violates unique constraint "SYS_INDEX_TRUCK_UNIQUE_TRUCK_EMAIL""
Now we will create new unique email address and insert a new record to table TRUCK:
-- Create new unique email address
SET NEW_UNIQUE_EMAIL = CONCAT($NEW_TRUCK_ID, '_truck@email.com');
insert into TRUCK values ($NEW_TRUCK_ID,2,'Stockholm','Stockholm län','Stockholm','Sweden','SE',1,2001,'Freightliner','MT45 Utilimaster',0,276,'2020-10-01',$NEW_UNIQUE_EMAIL,CURRENT_TIMESTAMP());
Statement should run successfully.
Step 4.2 Insert Foreign Keys Constraints
In this step we will test foreign key constraint.
First, let's recall the foreign key constraints we defined in the ORDER_HEADER table by executing the GET_DDL. Note the foreign key constraints related to the TRUCK_ID column in the output.
-- Return the DDL used to create table named ORDER_HEADER:
select get_ddl('table', 'ORDER_HEADER');
Second, we will try to insert a new record to table ORDER_HEADER with non existing truck id. It is expected that the insert statement would fail since we will violate the TRUCK table foreign key constraint.
-- Since ORDER_ID is a primary key we need to calculate a new primary key value in order not to fail on the "Primary key already exists" error.
SET MAX_ORDER_ID = (SELECT MAX(ORDER_ID) FROM ORDER_HEADER);
--Increment max ORDER_ID by one
SET NEW_ORDER_ID = ($MAX_ORDER_ID +1);
SET NONE_EXIST_TRUCK_ID = -1;
-- Insert new record to table ORDER_HEADER
insert into ORDER_HEADER values ($NEW_ORDER_ID,$NONE_EXIST_TRUCK_ID,6090,0,0,0,'16:00:00','23:00:00','','2022-02-18 21:38:46.000','','USD',17.0000,'','',17.0000,'');
The statement should fail and we should receive the following error message:
Foreign key constraint "SYS_INDEX_ORDER_HEADER_FOREIGN_KEY_TRUCK_ID_TRUCK_TRUCK_ID" is violated.
Now we will use the new NEW_TRUCK_ID variable we used in previous step and insert a new record to table ORDER_HEADER:
-- Insert new record to table ORDER_HEADER
insert into ORDER_HEADER values ($NEW_ORDER_ID,$NEW_TRUCK_ID,6090,0,0,0,'16:00:00','23:00:00','','2022-02-18 21:38:46.000','','USD',17.0000,'','',17.0000,'');
Statement should run successfully.
Step 4.3 Truncated Active Foreign Key Constraint
In this step, we will test that the table referenced by a foreign key constraint cannot be truncated as long as the foreign key relationship exists. To test it run the following TRUNCATE statement:
-- truncate the table
TRUNCATE TABLE TRUCK;
The statement should fail and we should receive the following error message: "391458 (0A000): Hybrid table ‘TRUCK' cannot be truncated as it is involved in active foreign key constraints."
Step 4.4 Delete Foreign Key Constraint
In this step, we will test that a record referenced by a foreign key constraint cannot be deleted as long as the foreign key reference relationship exists.
To test it run the following DELETE statement:
DELETE FROM TRUCK WHERE TRUCK_ID = $NEW_TRUCK_ID;
The statement should fail and we should receive the following error message: "Foreign keys that reference key values still exist."
To successfully delete a record referenced by a foreign key constraint, you must first delete the corresponding reference record in the ORDER_HEADER table. Only after completing this step you can proceed to delete the referenced record in the TRUCK table. To test this, execute the following DELETE statements:
DELETE FROM ORDER_HEADER WHERE ORDER_ID = $NEW_ORDER_ID;
DELETE FROM TRUCK WHERE TRUCK_ID = $NEW_TRUCK_ID;
Both statements should run successfully.
Unlike standard tables, which utilize partition or table-level locking, hybrid tables employ row-level locking for update operations. Row Level locking allows for concurrent updates on independent records. In this step, we will test concurrent updates to different records.
In order to test it we will run concurrent updates on two different records in the hybrid table ORDER_HEADER. We will use the main worksheet "Hybrid Table - QuickStart" we created in step 2.1 and will create a new worksheet "Hybrid Table - QuickStart session 2" to simulate a new session. From the "Hybrid Table - QuickStart" worksheet we will start a new transaction using the BEGIN statement, and run an update DML statement. Before running the COMMIT transaction statement we will open the "Hybrid Table - QuickStart session 2" worksheet and run another update DML statement. finally we will commit the open transaction.
Step 5.1 Creating a New Worksheet
Within Worksheets, click the "+" button in the top-right corner of Snowsight and choose "SQL Worksheet"
Rename the Worksheet by clicking on the auto-generated Timestamp name and inputting "Hybrid Table - QuickStart session 2". The "Hybrid Table - QuickStart Session 2" worksheet that we have just created will only be used in the current step.
Step 5.2 Running concurrent updates
Open "Hybrid Table - QuickStart" worksheet and then select and set MAX_ORDER_ID variable.
-- Step 5
-- Set step context
USE ROLE HYBRID_QUICKSTART_ROLE;
USE WAREHOUSE HYBRID_QUICKSTART_WH;
USE DATABASE HYBRID_QUICKSTART_DB;
USE SCHEMA DATA;
SET MAX_ORDER_ID = (SELECT max(order_id) from ORDER_HEADER);
SELECT $MAX_ORDER_ID;
Note the MAX_ORDER_ID variable value.
Start a new transaction and run the first update DML statement.
-- Begins a transaction in the current session.
BEGIN;
-- Update record
UPDATE ORDER_HEADER
SET order_status = 'COMPLETED'
WHERE order_id = $MAX_ORDER_ID;
Note that we didn't commit the transaction so now there is an open lock on the record WHERE order_id = $MAX_ORDER_ID.
Run SHOW TRANSACTIONS statement. It is expected that the SHOW TRANSACTIONS statement would return 1 single open transaction.
-- List all running transactions
SHOW TRANSACTIONS;
Now open the "Hybrid Table - QuickStart session 2" worksheet and then select and set MIN_ORDER_ID variable.
-- Step 5
-- Set step context
USE ROLE HYBRID_QUICKSTART_ROLE;
USE WAREHOUSE HYBRID_QUICKSTART_WH;
USE DATABASE HYBRID_QUICKSTART_DB;
USE SCHEMA DATA;
SET MIN_ORDER_ID = (SELECT min(order_id) from ORDER_HEADER);
SELECT $MIN_ORDER_ID;
Note that the MIN_ORDER_ID variable value is different from the MAX_ORDER_ID variable value we used in the first update DML statement.
Run second update DML statement.
-- Update record
UPDATE ORDER_HEADER
SET order_status = 'COMPLETED'
WHERE order_id = $MIN_ORDER_ID;
Since hybrid tables employ row-level locking and the open transaction locks the row WHERE order_id = $MAX_ORDER_ID the update statement should run successfully.
Open "Hybrid Table - QuickStart" worksheet and run a commit statement to commit the open transaction.
-- Commits an open transaction in the current session.
COMMIT;
Run the following statement to view the updated records:
SELECT * from ORDER_HEADER where order_status = 'COMPLETED';
In this step, we will demonstrate a unique hybrid tables feature that shows how we can run multi-statement operations natively, easily and effectively in one consistent atomic transaction across both hybrid and standard table types. We'll execute a use case where a truck owner acquires a new truck of the same model. Consequently we will have to update the YEAR column for relevant record in the TRUCK hybrid table to reflect the change. As a result of this update, the TRUCK_HISTORY standard table will be promptly updated to track and preserve changes over time.
Step 6.1 Run Multi Statement Transaction
First We'll initiate a new transaction using the BEGIN to ensure that the series of operations is treated as a single, atomic unit.
Second We'll execute a multi-statement DML that will:
- Update the relevant truck record in the TRUCK hybrid table.
- Update the corresponding record in the TRUCK_HISTORY table by setting the RECORD_END_TIME to mark the end of its validity.
- Insert a new record in the TRUCK_HISTORY table, capturing the updated information.
Finally, COMMIT the transaction.
-- Step 6
-- Set step context
USE ROLE HYBRID_QUICKSTART_ROLE;
USE WAREHOUSE HYBRID_QUICKSTART_WH;
USE DATABASE HYBRID_QUICKSTART_DB;
USE SCHEMA DATA;
-- Begins a transaction in the current session.
begin;
-- Set current timestamp. We will use it to set timestamp columns.
SET CURRENT_TIMESTAMP = CURRENT_TIMESTAMP();
-- Update YEAR and RECORD_START_TIME columns for the relevant truck record in the TRUCK Hybrid table.
update TRUCK set YEAR = '2024',RECORD_START_TIME=$CURRENT_TIMESTAMP where TRUCK_ID = 1;
-- Update the corresponding record in the TRUCK_HISTORY table by setting the RECORD_END_TIME to mark the end of its validity.
update TRUCK_HISTORY SET RECORD_END_TIME=$CURRENT_TIMESTAMP where TRUCK_ID = 1 and RECORD_END_TIME IS NULL;
-- Insert a new record in the TRUCK_HISTORY table, capturing the updated information.
insert into TRUCK_HISTORY select *,NULL AS RECORD_END_TIME from TRUCK where TRUCK_ID = 1;
-- commit the transaction
commit;
Step 6.3 Explore Data
Now we can run select queries to review the new inserted records.
-- Should return two records
select * from TRUCK_HISTORY where TRUCK_ID = 1;
-- Should return one updated record
select * from TRUCK where TRUCK_ID = 1;
In this step, we will test the join between hybrid and standard tables. We will use the TRUCK_HISTORY table and join it with the hybrid table ORDER_HEADER.
Step 7.1 Explore Data
In the Setup step, we already created and loaded data into the ORDER_HEADER tables. Now we can run a few queries and review some information to get familiar with it.
-- Step 7
-- Set step context
USE ROLE HYBRID_QUICKSTART_ROLE;
USE WAREHOUSE HYBRID_QUICKSTART_WH;
USE DATABASE HYBRID_QUICKSTART_DB;
USE SCHEMA DATA;
-- Lists the tables for which you have access privileges in hybrid_quickstart_db database
show tables in database hybrid_quickstart_db;
-- Select name and is_hybrid columns
select "name", "is_hybrid" from table(result_scan(last_query_id()));
-- Simple query to look at 10 rows of data from standard table TRUCK_HISTORY
select * from TRUCK_HISTORY limit 10;
-- Simple query to look at 10 rows of data from hybrid table ORDER_HEADER
select * from ORDER_HEADER limit 10;
Step 7.2 Join Hybrid Table and Standard Table
In order to test the join of the hybrid table ORDER_HEADER with the standard table TRUCK_HISTORY, let's run the join statement.
-- Set ORDER_ID variable
set ORDER_ID = (select order_id from ORDER_HEADER limit 1);
-- Join tables ORDER_STATE_HYBRID and TRUCK_HISTORY
select HY.*,ST.* from ORDER_HEADER as HY join TRUCK_HISTORY as ST on HY.truck_id = ST.TRUCK_ID where HY.ORDER_ID = $ORDER_ID and ST.RECORD_END_TIME IS NULL;
After executing the join statement, examine and analyze the data in the result set.
In this step, we will demonstrate that the security and governance functionalities applied to the standard table also extend to the hybrid table, by running two security use cases.
Step 8.1 Hybrid Table Access Control and User Management
Role-based access control (RBAC) in Snowflake for hybrid tables is the same as standard tables. The purpose of this exercise is to give you a chance to see how you can manage access to hybrid table data in Snowflake by granting privileges to some roles.
First we will create a new HYBRID_QUICKSTART_BI_USER_ROLE role
-- Step 8
-- Set step context
USE ROLE HYBRID_QUICKSTART_ROLE;
USE WAREHOUSE HYBRID_QUICKSTART_WH;
USE DATABASE HYBRID_QUICKSTART_DB;
USE SCHEMA DATA;
USE ROLE ACCOUNTADMIN;
CREATE ROLE HYBRID_QUICKSTART_BI_USER_ROLE;
SET MY_USER = CURRENT_USER();
GRANT ROLE HYBRID_QUICKSTART_BI_USER_ROLE TO USER IDENTIFIER($MY_USER);
Then we will grant USAGE privileges to HYBRID_QUICKSTART_WH warehouse, HYBRID_QUICKSTART_DB database, and all its schemas to role HYBRID_QUICKSTART_BI_USER_ROLE
-- Use HYBRID_QUICKSTART_ROLE role
USE ROLE HYBRID_QUICKSTART_ROLE;
GRANT USAGE ON WAREHOUSE HYBRID_QUICKSTART_WH TO ROLE HYBRID_QUICKSTART_BI_USER_ROLE;
GRANT USAGE ON DATABASE HYBRID_QUICKSTART_DB TO ROLE HYBRID_QUICKSTART_BI_USER_ROLE;
GRANT USAGE ON ALL SCHEMAS IN DATABASE HYBRID_QUICKSTART_DB TO HYBRID_QUICKSTART_BI_USER_ROLE;
Use the newly created role and try to select some data from ORDER_STATE_HYBRID hybrid table
-- Use HYBRID_QUICKSTART_BI_USER_ROLE role
USE ROLE HYBRID_QUICKSTART_BI_USER_ROLE;
-- Use HYBRID_QUICKSTART_BI_USER_ROLE database
USE DATABASE HYBRID_QUICKSTART_DB;
USE SCHEMA DATA;
select * from ORDER_HEADER limit 10;
We're not able to select any data. That's because the role HYBRID_QUICKSTART_BI_USER_ROLE has not been granted the necessary privileges.
Use role HYBRID_QUICKSTART_ROLE and grant role HYBRID_QUICKSTART_BI_USER_ROLE select privileges on all tables in schema DATA.
-- Use HYBRID_QUICKSTART_ROLE role
USE ROLE HYBRID_QUICKSTART_ROLE;
GRANT SELECT ON ALL TABLES IN SCHEMA DATA TO ROLE HYBRID_QUICKSTART_BI_USER_ROLE;
Try again to select some data from ORDER_STATE_HYBRID hybrid table
-- Use HYBRID_QUICKSTART_BI_USER_ROLE role
USE ROLE HYBRID_QUICKSTART_BI_USER_ROLE;
select * from ORDER_HEADER limit 10;
This time it worked! This is because the HYBRID_QUICKSTART_BI_USER_ROLE role has the appropriate privileges at all levels of the hierarchy.
Step 8.2 Hybrid Table Masking Policy
In this step, we will create a new masking policy object and apply it to the TRUCK_EMAIL column in the TRUCK hybrid table using an ALTER TABLE... ALTER COLUMN statement.
First, we will create a new masking policy.
-- Step 8
-- Set step context
USE ROLE HYBRID_QUICKSTART_ROLE;
USE WAREHOUSE HYBRID_QUICKSTART_WH;
USE DATABASE HYBRID_QUICKSTART_DB;
USE SCHEMA DATA;
--full column masking version, always masks
create masking policy hide_column_values as
(col_value varchar) returns varchar ->
case
WHEN current_role() IN ('HYBRID_QUICKSTART_ROLE') THEN col_value
else '***MASKED***'
end;
Apply the policy to the hybrid table.
-- set masking policy
alter table TRUCK modify column TRUCK_EMAIL
set masking policy hide_column_values using (TRUCK_EMAIL);
Since we are using the HYBRID_QUICKSTART_ROLE role column TRUCK_EMAIL should not be masked. Run the statement to see if it has the desired effect
select * from TRUCK limit 10;
Since we are using HYBRID_QUICKSTART_BI_USER_ROLE role column TRUCK_EMAIL should be masked. Run the statement to see if it has the desired effect
-- Use HYBRID_QUICKSTART_BI_USER_ROLE role
USE ROLE HYBRID_QUICKSTART_BI_USER_ROLE;
select * from TRUCK limit 10;
To clean up your Snowflake environment you can run the following SQL Statements:
-- Step 9
-- Set step context
USE ROLE HYBRID_QUICKSTART_ROLE;
USE WAREHOUSE HYBRID_QUICKSTART_WH;
USE DATABASE HYBRID_QUICKSTART_DB;
USE SCHEMA DATA;
DROP DATABASE HYBRID_QUICKSTART_DB;
DROP WAREHOUSE HYBRID_QUICKSTART_WH;
USE ROLE ACCOUNTADMIN;
DROP ROLE HYBRID_QUICKSTART_ROLE;
DROP ROLE HYBRID_QUICKSTART_BI_USER_ROLE;
The last step is to manually delete "Hybrid Table - QuickStart" and "Hybrid Table - QuickStart session 2" worksheets.
What You Learned
Having completed this quickstart you have successfully
- Created Hybrid Table and Bulk Load Data
- Explore the Data
- Learned about Unique and Foreign Keys Constraints
- Learned about hybrid table unique row level locking
- Learned about consistency and how you can run multi-statement operation in one consistent atomic transaction across both hybrid and standard table types
- Learned about hybrid querying and how to join standard table and hybrid table
- Learned that security and governance principles apply similarly to both hybrid and standard tables